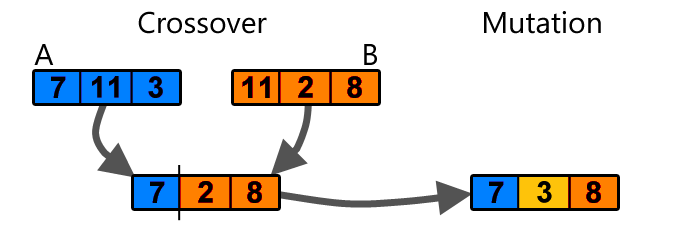 |
Web Demo
Demo ini akan mencoba untuk menggunakan algoritma genetika untuk menghasilkan struktur jaringan saraf efisien, tetapi atipikal untuk mengklasifikasikan set data yang dipinjam dari TensorFlow Playground. Silakan coba demo di sini.
|
Motivasi
Beberapa minggu yang lalu, Google merilis Demo Web disebut TensorFlow Playground. Jika Anda tidak bermain dengan itu belum, saya mendorong Anda untuk melakukannya, karena ini adalah web demo yang benar-benar baik dirancang menampilkan kemajuan pelatihan tentang bagaimana jaringan saraf menangani masalah klasifikasi sederhana dengan beberapa dataset dummy. Anda bisa menyesuaikan banyak aspek dari jaringan, seperti jumlah lapisan, neuron per layer dan fungsi aktivasi, fitur input awal, dan sebagainya.
Salah satu hal yang tertarik saya adalah umpan balik dari pengguna demo itu. Orang-orang mulai bereksperimen dengan konfigurasi jaringan saraf yang berbeda, seperti berapa banyak lapisan jaringan saraf yang benar-benar diperlukan untuk memenuhi satu set data tertentu, atau apa fitur awal harus digunakan untuk kumpulan data lain. Yang berfungsi aktivasi bekerja lebih baik untuk yang dataset?
Dalam masalah klasifikasi berbasis jaringan saraf yang khas, ilmuwan data yang akan merancang dan mengumpulkan beberapa jaringan saraf yang telah ditentukan, berdasarkan heuristik manusia, dan sedikit pembelajaran mesin yang sebenarnya tugas akan memecahkan set bobot dalam jaringan , menggunakan beberapa varian dari stochastic gradien keturunan dan algoritma propagasi kembali untuk menghitung gradien berat, dalam rangka untuk mendapatkan jaringan untuk menyesuaikan beberapa data pelatihan di bawah beberapa kendala regularisasi. The TensorFlow Playground demo menangkap esensi dari semacam ini tugas, tapi aku sudah berpikir jika mesin pembelajaran juga dapat digunakan secara efektif untuk merancang jaringan saraf yang sebenarnya digunakan untuk tugas yang diberikan juga. Bagaimana jika kita dapat mengotomatisasi proses menemukan arsitektur jaringan saraf?
Aku memutuskan untuk bereksperimen dengan ide ini dengan menciptakan demo ini. Daripada pergi dengan pendekatan konvensional mengorganisir banyak lapisan neuron dengan fungsi aktivasi seragam, kita akan mencoba untuk meninggalkan ide lapisan sama sekali, sehingga setiap neuron berpotensi dapat terhubung ke neuron lain dalam jaringan kami. Juga, bukan menempel dengan neuron yang menggunakan fungsi aktivasi seragam, seperti sigmoids atau relu, kami akan memungkinkan banyak jenis neuron dengan berbagai jenis fungsi aktivasi, seperti sigmoid, tanh, relu, sinus, gaussian, abs, persegi, dan bahkan penambahan dan gerbang perkalian.
algoritma genetika disebut NEAT akan digunakan untuk berevolusi jaring saraf kita dari yang sangat sederhana di awal untuk yang lebih kompleks selama beberapa generasi. Bobot dari jaring saraf akan diselesaikan melalui propagasi kembali. The recurrent.js perpustakaan mengagumkan dibuat oleh karpathy, memungkinkan untuk membangun representasi grafik komputasi dari jaringan saraf yang sewenang-wenang dengan fungsi aktivasi yang sewenang-wenang. Saya menerapkan algoritma NEAT untuk menghasilkan representasi dari jaring saraf yang recurrent.js dapat memproses, sehingga perpustakaan dapat digunakan untuk meneruskan melewati jaring saraf yang NEAT telah ditemukan, dan juga untuk backprop jaring saraf untuk mengoptimalkan bobot mereka.
Pengantar Neuroevolution
Kebanyakan mahasiswa yang belajar mesin belajar belajar bahwa untuk melatih jaringan saraf, seseorang harus menentukan fungsi tujuan untuk mengukur seberapa baik jaringan saraf melakukan beberapa tugas, dan menggunakan kembali propagasi untuk memecahkan derivatif dari fungsi tujuan ini dengan masing-masing untuk masing-masing berat badan, dan setelah menggunakan gradien ini untuk iteratif memecahkan baik set bobot untuk jaringan saraf. Kerangka ini dikenal sebagai pelatihan end-to-end.
Sedangkan algoritma propagasi kembali saat ini metode yang paling ampuh untuk banyak aplikasi, hal ini tentunya bukan satu-satunya metode. Ada metode lain untuk datang dengan bobot jaringan syaraf. Misalnya, pergi ke salah satu ekstrim, satu metode adalah hanya untuk secara acak menebak bobot dari jaringan saraf sampai kita mendapatkan satu set bobot yang dapat membantu kita melakukan beberapa tugas.
algoritma genetika adalah langkah yang sangat sederhana di luar menebak acak. Ia bekerja sebagai berikut: Bayangkan jika kita memiliki satu set 100 bobot acak untuk jaringan saraf, dan mengevaluasi jaringan saraf dengan setiap set bobot untuk melihat seberapa baik melakukan tugas tertentu. Setelah melakukan hal ini, kita tetap hanya yang terbaik 20 set beban. Kami membentuk kembali setiap set bobot ke dalam array satu dimensi. Kemudian, kita bisa mengisi 80 set sisa bobot secara acak memilih dari 20 yang kita terus, dan menerapkan crossover dan mutasi sederhana operasi untuk membentuk satu set baru bobot:
Set baru 80 bobot akan ada beberapa kombinasi bermutasi dari 20, dan setelah kami memiliki set lengkap 100 bobot lagi, kita dapat mengulangi tugas mengevaluasi jaringan saraf dengan masing-masing set beban lagi dan ulangi proses evolusi sampai kita mendapatkan satu set bobot yang memenuhi kebutuhan kita.
Jenis algoritma adalah contoh dari Neuroevolution, dan sangat berguna untuk memecahkan untuk bobot jaringan saraf ketika sulit untuk menentukan fungsi tujuan matematis berperilaku baik, seperti fungsi tanpa derivatif yang jelas. Menggunakan tipe sederhana ini metode di masa lalu, saya telah berhasil melatih jaringan saraf untuk menyeimbangkan pendulum terbalik, bermain lendir voli, dan agen untuk bersama belajar untuk menghindari rintangan.
Meskipun metode ini mudah diterapkan dan mudah digunakan, itu tidak benar-benar baik skala, terutama ketika ukuran jaringan adalah luar ribu sambungan. Otak agen voli hanya terdiri dari selusin fungsi aktivasi. metode modern seperti Deep Q Learning, dan gradien kebijakan juga akan memungkinkan kita untuk melatih (lebih besar) jaringan untuk tugas-tugas kontrol ini, atau tugas bermain game menggunakan kembali propagasi. Yang sedang berkata, aku yakin agen voli sederhana saya masih akan menendang DQN pantat :-)
Penelitian di Deep Learning dalam beberapa tahun terakhir telah memberi kita banyak alat yang berguna untuk menggunakan backprop efisien untuk banyak tugas pembelajaran mesin. Selain regularisasi berat badan, kita harus putus sekolah, rmsprop, bets normalisasi, dll untuk beberapa nama. Jadi saya merasa bahwa backprop akan terus menjadi bagian yang sangat berguna dari jaringan pelatihan saraf di masa depan, sebagai peneliti menemukan metode untuk membingkai lebih banyak masalah dalam kerangka end-to-end.
Selain berat pencarian, penelitian mendalam Learning juga telah menghasilkan banyak arsitektur jaringan saraf yang kuat yang blok bangunan penting. Secara historis, kebanyakan arsitektur jaringan syaraf telah tangan direkayasa oleh pikiran cemerlang. Misalnya, gerbang LSTM yang kerajinan tangan untuk menghindari masalah gradien meledak untuk RNNs. Convnets diciptakan untuk meminimalkan jumlah koneksi yang dibutuhkan untuk masalah visi komputer. ResNets dirancang untuk dapat menumpuk banyak lapisan jaring saraf secara efektif. Biasanya, setelah arsitektur baru seperti yang ditemukan dan diadaptasi dalam penelitian akademik utama, peneliti lain akan melihat ke belakang dan menyadari betapa sederhana penemuan sebenarnya dan menyesal bahwa mereka tidak bisa menjadi yang pertama untuk datang dengan ide.
Saya pikir saraf desain arsitektur jaringan adalah area di mana Neuroevolution dapat menjadi alat yang berguna. algoritma genetika tidak berhenti pada sekedar mampu menemukan saraf bobot koneksi jaringan. Hal ini juga dapat diperpanjang untuk menemukan seluruh jaringan saraf. Saya pikir mendapatkan komputer untuk dapat secara otomatis menemukan Novel arsitektur jaringan saraf adalah ide yang benar-benar keren, dan jadi saya membuat demo sederhana ini untuk mengeksplorasi konsep ini.
Topologi Jaringan Neural Berkembang
Neuroevolution dari menambah Topologi (NEAT) adalah metode yang dapat berkembang jenis baru dari jaringan saraf berdasarkan algoritma genetika. Itu diterbitkan lebih dari satu dekade lalu oleh Ken Stanley, dan sangat populer di kalangan masyarakat pinggiran kecil peneliti AI berfokus pada komputasi evolusi. komputasi evolusi ini tentunya tidak populer dalam penelitian pembelajaran mesin utama, di mana pembelajaran dalam mendominasi. peneliti belajar dalam adalah seperti idola pop di masyarakat AI, sementara peneliti pinggiran lebih seperti beberapa garasi jelas band metal indie bahwa tidak ada yang mendengar.
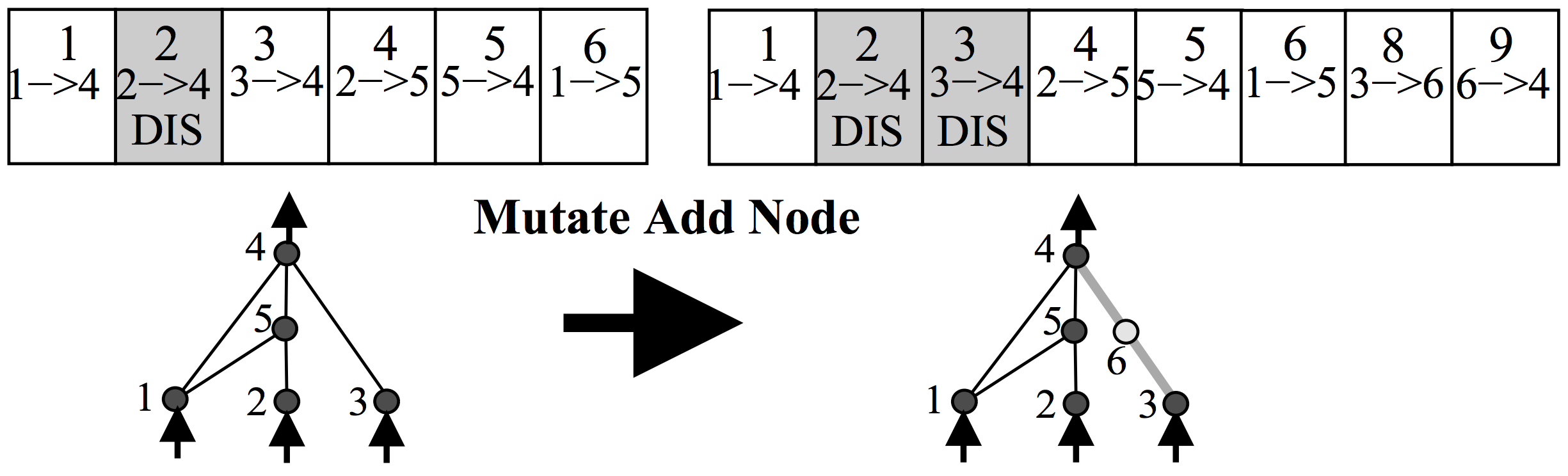
Anyways, cara kerja NEAT adalah untuk mewakili jaringan saraf sebagai daftar koneksi. Pada awalnya, populasi awal jaringan akan memiliki arsitektur yang sangat sederhana, seperti memiliki masing-masing sinyal input dan bias hanya terhubung secara langsung ke output tanpa lapisan tersembunyi. Dalam operasi mutasi, ada beberapa kemungkinan bahwa neuron baru akan bisa dibuat. Sebuah neuron baru akan ditempatkan di antara koneksi yang ada, maka koneksi baru akan dibuat setelah pengenalan neuron baru, seperti di bawah ini:
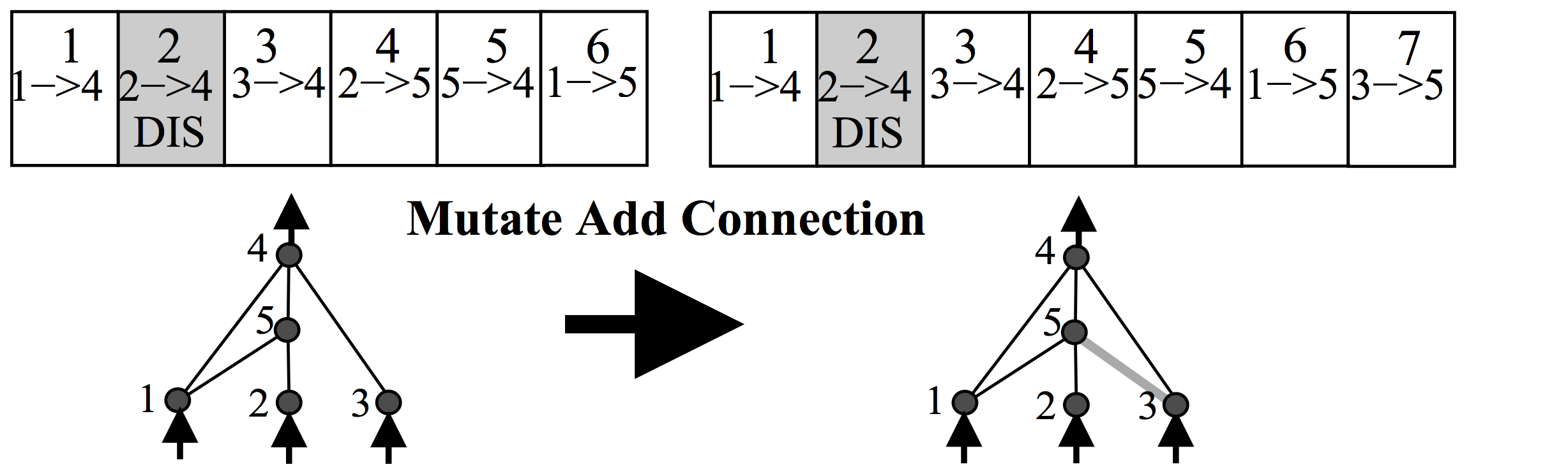
Ada juga beberapa kemungkinan bahwa sambungan baru akan diciptakan dalam operasi mutasi yang sama, seperti di bawah ini:
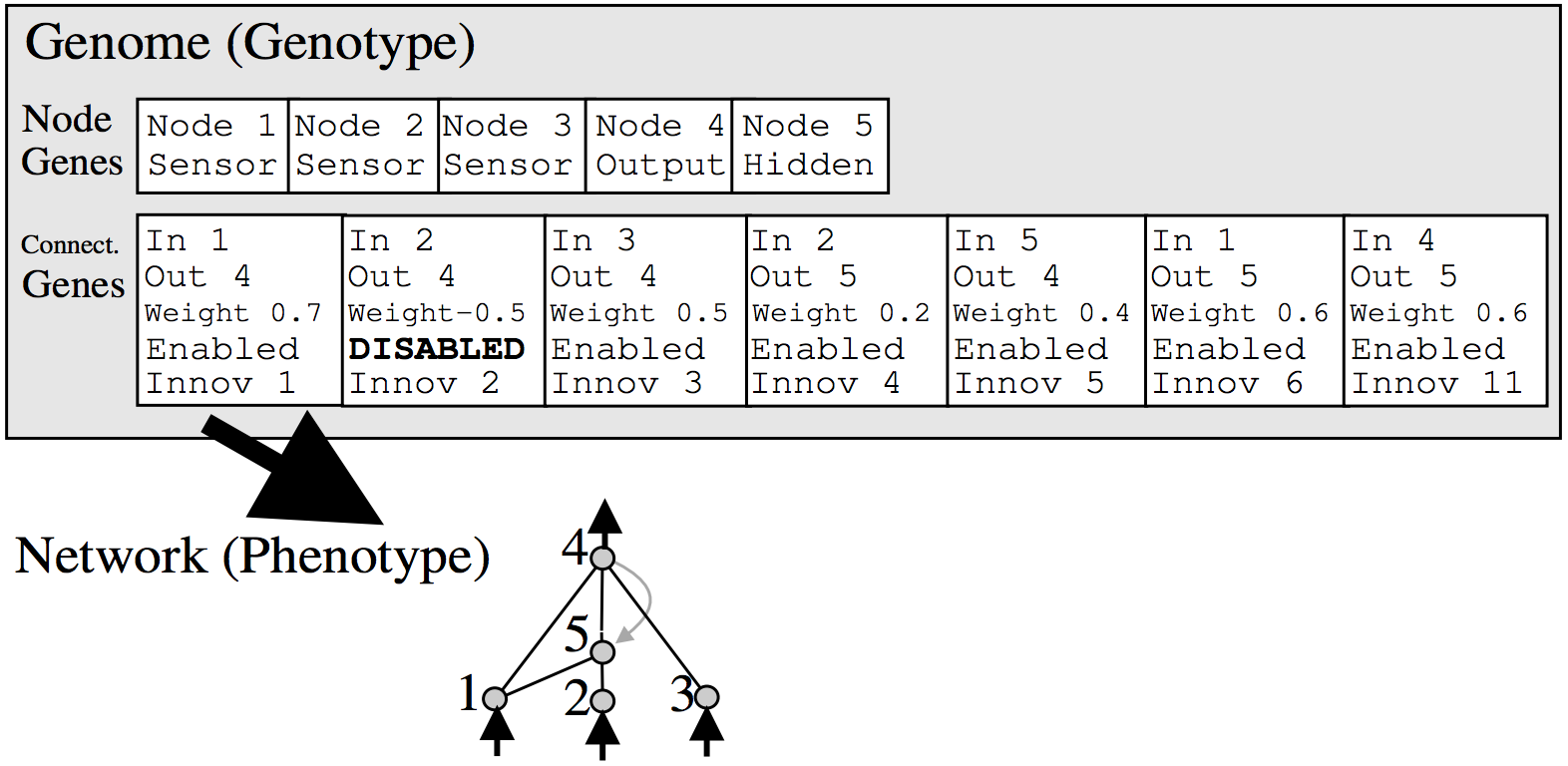
Setiap neuron dan koneksi di seluruh populasi adalah unik, dan diberi label bilangan bulat unik. Jadi setiap jaringan hanya saja daftar koneksi, bersama dengan berat untuk koneksi mereka. Perhatikan bahwa dua jaringan yang berbeda dapat memiliki koneksi yang sama, tetapi bobot untuk masing-masing jaringan umumnya akan berbeda.
Karena setiap neuron dan setiap koneksi secara global unik, menjadi mungkin untuk menggabungkan dua jaringan yang berbeda, untuk menghasilkan jaringan baru. Ini adalah bagaimana operasi crossover dilakukan di NEAT:
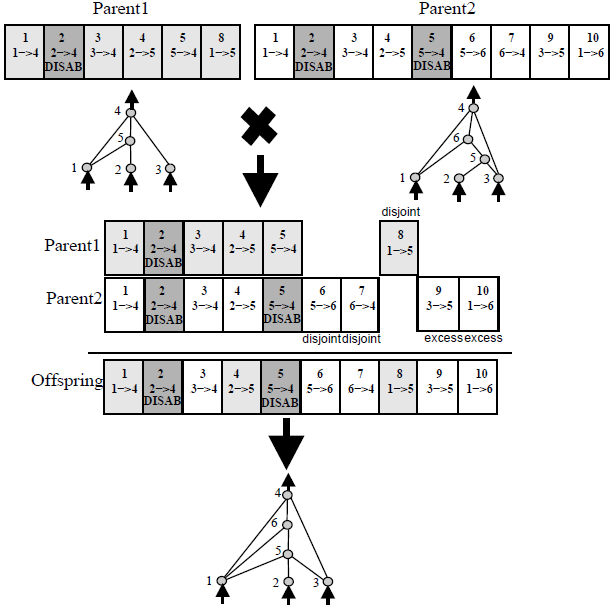 |
| Semua diagram dari kertas NEAT asli, sangat dianjurkan membaca! |
Crossover operasi cukup kuat. Jika kita memiliki jaringan yang baik di beberapa sub tugas, dan jaringan lain yang baik di beberapa sub tugas lain, kita mungkin dapat berkembang biak jaringan keturunan yang berpotensi dapat menjadi baik menggabungkan kedua keterampilan dan menjadi jauh lebih baik daripada kedua orang tua jaringan dalam melakukan tugas yang lebih besar.
Sekarang bahwa mutasi dan crossover yang operasi didefinisikan, kita hanya dapat menggunakan algoritma genetika saya jelaskan sebelumnya untuk menemukan jaringan baru berkembang mereka melalui banyak generasi! Kami belum ada di sana, namun, karena ada lebih dari ini operator genetik dalam algoritma NEAT.
spesiasi
Dalam komputasi evolusioner, spesiasi adalah ide untuk kelompok populasi gen ke dalam spesies yang berbeda yang terdiri dari anggota yang sama dari populasi. Idenya adalah untuk memberikan beberapa anggota populasi, yang mungkin tidak menjadi yang terbaik dalam melakukan tugas, tapi lihat dan berperilaku sangat berbeda dari mereka yang saat ini yang terbaik, lebih banyak waktu untuk berkembang untuk potensi penuh mereka, bukan untuk membunuh mereka off di setiap generasi.
Bayangkan sebuah pulau terisolasi dihuni oleh serigala dan penguin saja. Jika kita membiarkan hal-hal menjadi, penguin akan daging mati setelah generasi pertama dan semua kita akan ditinggalkan dengan serigala. Tetapi jika kita membuat khusus tidak ada zona membunuh di pulau di mana serigala tidak diperbolehkan untuk membunuh penguin setelah mereka melangkah masuk daerah itu, sejumlah penguin akan selalu ada, dan punya waktu untuk berkembang menjadi penguin terbang yang akan membuat jalan mereka kembali ke daratan di mana ada banyak tumbuhan untuk hidup, sementara serigala akan terjebak selamanya di pulau. Hal ini juga mungkin bagi beberapa serigala aneh dengan krisis identitas jatuh cinta dengan seekor penguin dan memulai sebuah keluarga bersama-sama di zona itu, dan jadi kita juga berakhir dengan terbang serigala-penguin yang akhirnya akan mendominasi daratan. Spesiasi adalah konsep yang kuat dalam evolusi buatan.
Untuk contoh yang lebih konkret, pertimbangkan contoh sebelumnya tentang 100 set bobot, dan bayangkan jika kita memodifikasi algoritma dari hanya menjaga yang terbaik 20 dan menyingkirkan sisanya, untuk pertama pengelompokan 100 bobot menjadi 5 kelompok sesuai dengan kesamaan oleh, mengatakan, menggunakan jarak euclidean antara bobot mereka. Sekarang bahwa kita memiliki 5 kelompok, atau spesies, dari 20 jaringan, untuk setiap kelompok kami akan tetap hanya bagian atas 20% lagi (jadi kita tetap 4 set bobot untuk setiap spesies), dan menyingkirkan sisa 16. Dari sana, kita bisa baik memutuskan untuk mengisi sisa 16 oleh crossover bermutasi 4 anggota yang tersisa dari setiap spesies, atau dari seluruh himpunan anggota yang masih hidup di populasi yang lebih besar. Dengan memodifikasi algoritma genetika cara ini untuk memungkinkan spesiasi, jenis tertentu dari gen memiliki waktu untuk mengembangkan potensi penuh mereka, dan juga keragaman akan menyebabkan gen yang lebih baik yang menggabungkan yang terbaik dari jenis yang berbeda yang berbeda dari spesies. Tanpa spesiasi, mudah bagi penduduk untuk terjebak pada optimum lokal.
Kertas NEAT juga didefinisikan metode untuk spesiasi. Ini didefinisikan operator jarak untuk mengukur seberapa berbeda satu jaringan ke jaringan lain. Pada dasarnya, ia menghitung jumlah koneksi yang tidak dimiliki oleh dua jaringan, dan koneksi yang saham, mengukur perbedaan bobot dalam koneksi umum, dan jarak antara dua jaringan adalah kombinasi linear dari faktor-faktor ini . Setelah kita dapat menghitung jarak antara setiap jaringan dalam populasi kami, NEAT menetapkan formula untuk jaringan kelompok yang berada dalam jarak tertentu bersama-sama untuk membentuk spesies, atau sub populasi. Makalah ini berisi beberapa ide tentang bagaimana untuk menangani dengan spesies yang berbeda, dan ketika spesies cross-breed dan membuat spesies tertentu akan punah jika Anda tertarik untuk membaca lebih jauh ke dalam rincian.
take pribadi saya adalah bahwa sementara konsep spesiasi penting, pelaksanaan yang tepat tentang bagaimana untuk mencapai spesiasi cukup fleksibel dan tidak ada de facto pendekatan yang benar. Dalam implementasi saya NEAT untuk demo ini, saya benar-benar diabaikan metode spesiasi NEAT ini, dan akhirnya menggunakan algoritma K-Medoids untuk membagi penduduk kita 100 jaringan menjadi 5 cluster berdasarkan jarak dihitung antara jaringan. Kita tidak bisa menggunakan K-cara pengelompokan karena kita hanya tahu jarak antara masing-masing jaringan, bukan lokasi yang tepat di ruang dimensi hiper. Pendekatan ini akhirnya bekerja cukup baik, dan tampaknya lebih elegan dan sederhana kepada saya untuk keperluan tugas klasifikasi sederhana dalam demo ini.
Backprop NEAT
Lupakan Torch, Tensorflow, dan Theano. Saya memutuskan untuk menerapkan Backprop NEAT di Javascript, karena dianggap bahasa terbaik untuk Deep Learning menurut data Sains Dojo.
Saya menerapkan porsi operator genetik dari NEAT untuk proyek sebelumnya disebut Neurogram, yang memungkinkan pengguna untuk secara interaktif berevolusi populasi jaringan saraf menggunakan NEAT bergaya crossover dan mutasi operator, untuk tujuan menciptakan seni genetik. Untuk menghasilkan gambar, koordinat setiap pixel dalam gambar yang akan menjadi masukan untuk jaringan saraf, dan output akan menjadi warna untuk itu sangat pixel. Semakin rumit jaringan, yang lebih rinci gambar yang dihasilkan akan.
Dalam pelaksanaannya kami NEAT, saya memungkinkan untuk berbagai jenis fungsi aktivasi, direpresentasikan sebagai warna yang berbeda dalam jaringan saraf. Berikut adalah legenda untuk fungsi aktivasi yang berbeda:
input | output | bias |
sigmoid | tanh | relu |
gaussian | sine | abs |
mult | add | square |
Operator add tidak apa-apa untuk input (yang merupakan jumlah tertimbang output dari koneksi yang masuk), sementara operator mult akan beberapa semua input tertimbang bersama-sama. Dengan memungkinkan operator sinusoidal, jaringan dapat menghasilkan pola berulang dalam output. Alun-alun dan abs operator berguna untuk menghasilkan simetri. Operator Gaussian dapat membantu untuk menarik satu-off wilayah berkerumun.
Dalam beberapa hal, masalah klasifikasi di TensorFlow Playground dapat dianggap sebagai bagian dari generasi gambar. Setiap datapoint pada set pelatihan sesuai dengan kelas (nol atau satu), dan masing-masing datapoint memiliki (x, y) koordinat. Jika kita memodifikasi program seni generasi output bilangan real antara nol dan satu, bukan tiga jalur warna, kita bisa mencoba untuk mencoba untuk mendapatkan program seni generasi hanya menggambar monoton, di mana daerah pada gambar monoton dengan intensitas di bawah 0,5 akan sesuai dengan prediksi dari nol dan daerah di atas 0,5 akan sesuai dengan prediksi dari satu.
Jadi itu cukup mudah untuk memodifikasi Neurogram kode NEAT dari gambar-generasi akan melakukan tugas klasifikasi. Satu-satunya hal yang perlu kita lakukan adalah untuk mengimplementasikan bagian algoritma genetika dari NEAT bersama dengan spesiasi, sehingga jaringan secara khusus berkembang agar sesuai dengan data training, daripada menghasilkan seni mewah.
Sejak pelaksanaan NEAT saya bekerja dengan menggambarkan jaringan saraf yang akhirnya dibangun sebagai grafik perhitungan yang dapat diproses oleh recurrent.js, kami juga akan dapat melakukan kembali propagasi dan mengoptimalkan bobot masing-masing arsitektur jaringan saraf individu terbaik sesuai pelatihan data. Dengan cara ini, NEAT secara ketat bertanggung jawab untuk mencari tahu arsitektur baru, sementara backprop dapat mencoba untuk menentukan set terbaik dari bobot untuk setiap arsitektur yang NEAT datang dengan. Dalam kertas NEAT asli, NEAT juga digunakan untuk mengetahui bobot serta menggunakan operasi algoritma genetika tapi saya pikir ini tidak efisien sama sekali, terutama ketika kita tahu backprop adalah metode yang superior untuk mencari tahu bobot untuk masalah klasifikasi sederhana . Dalam pelaksanaannya, saya juga menggabungkan L2 jangka regularisasi untuk bobot saat melakukan backprop pada setiap jaringan. Di masa depan, mungkin juga untuk menerapkan teknik lain seperti putus sekolah.
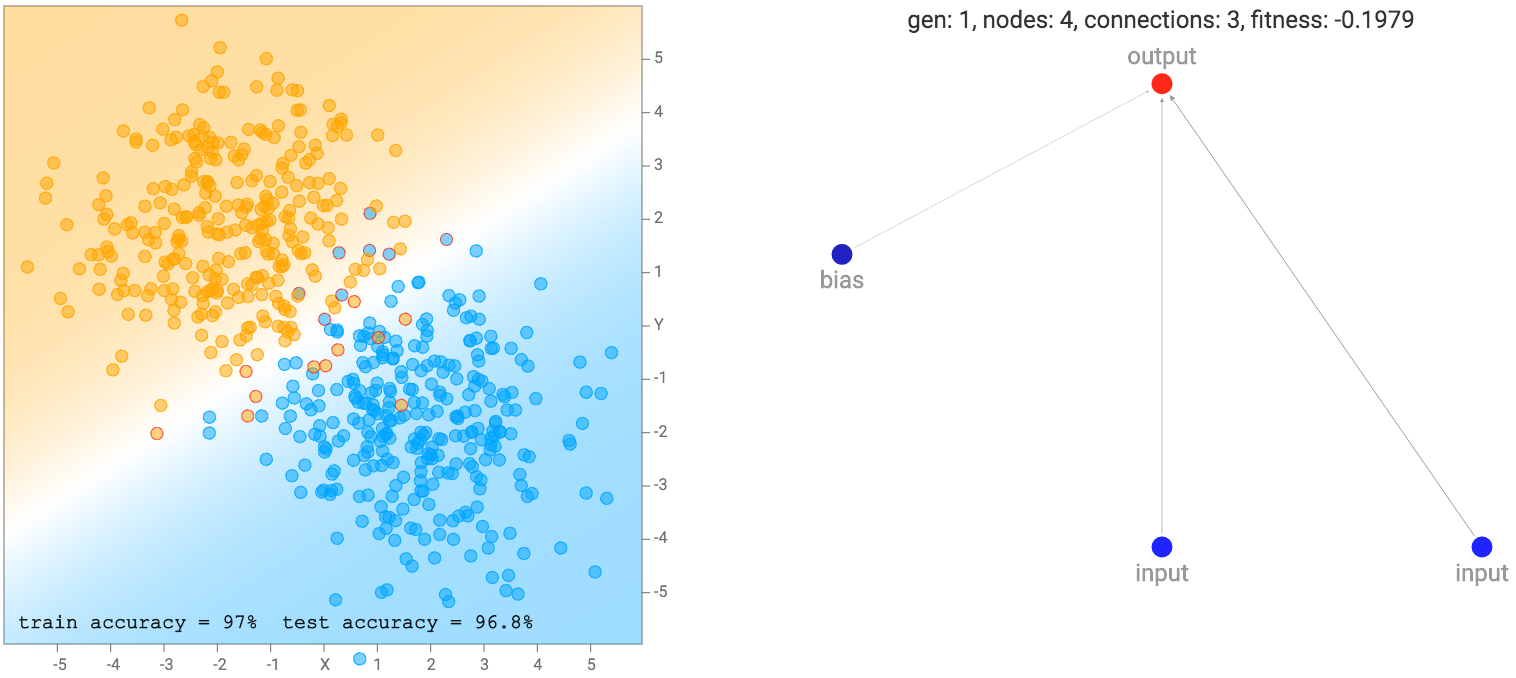
Pada awalnya, populasi jaringan akan memulai tampak sangat sederhana dan minim, seperti di bawah. Perhatikan bahwa untuk demo ini, output neuron juga operator sigmoid karena kita mengelompokkan kelas label sebagai nol atau satu. Jadi pada dasarnya generasi pertama jaringan semua jaringan regresi logistik dengan satu set yang berbeda dari bobot awal random.
output=σ(w
1
x+w
2
y+w
3
b)
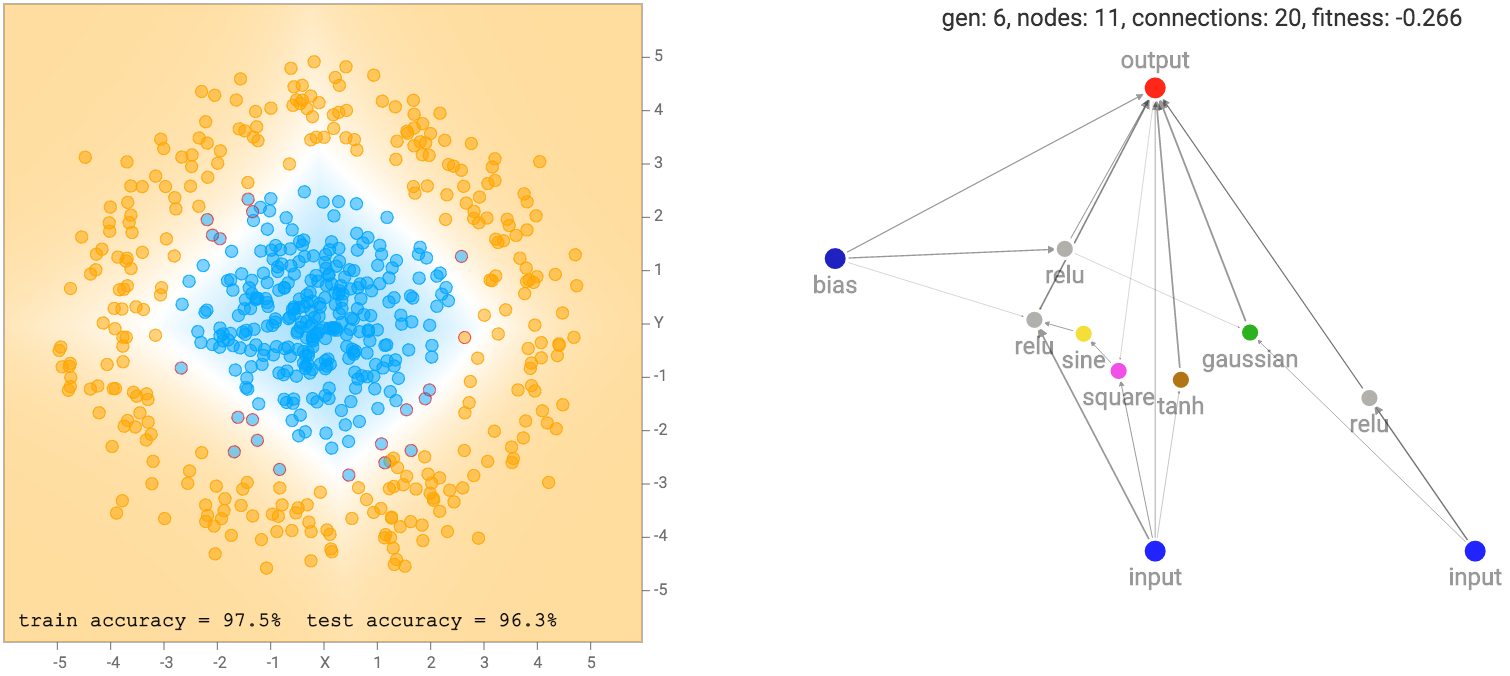
jaringan sederhana ini hanya kombinasi linear dari koordinat menjadi lapisan sigmoid hanya akan membagi pesawat menjadi garis seperti diagram di atas. Wilayah output yang mendekati nol akan dicat oranye. wilayah ini dekat dengan salah satu akan dicat biru, dan wilayah antara nol dan satu akan dicampur antara dua warna dan akan persis putih pada 0,5. Kami melihat bahwa ketika dataset adalah dua kelompok gaussian, jaringan standar yang paling sederhana akan tampil cukup baik sudah. Bahkan, kita mulai dengan populasi awal dari 100 jaringan sederhana dengan bobot random murni, dan sebelum melakukan backprop atau algoritma genetika dilakukan pada populasi, jaringan yang terbaik dalam populasi akan sudah cukup baik untuk jenis dataset .
Ketika mengevaluasi setiap jaringan, kita perlu menetapkan setiap jaringan dengan skor kebugaran pada seberapa baik itu, jadi kami dapat peringkat mereka dalam algoritma genetika. Selain melihat seberapa baik setiap jaringan sesuai dengan data pelatihan, menggunakan kemungkinan maksimum, jumlah koneksi juga akan mempengaruhi skor kebugaran jaringan. Kami akan lebih memilih jaringan sederhana melalui jaringan lebih rumit, jika mereka mencapai akurasi regresi yang sama, dan dalam beberapa kasus kita bahkan akan lebih jaringan yang lebih sederhana lebih yang sangat rumit bahkan jika satu sederhana sesuai dengan data pelatihan kurang akurat. Untuk mencapai hal ini, saya kalikan skor kebugaran dengan faktor yang tumbuh secara proporsional dengan akar kuadrat dari jumlah koneksi.
\ Displaystyle {kebugaran = -regression _ \; kesalahan * \ sqrt {1 + koneksi \; menghitung \; penalti * koneksi \; count}} kebugaran = -regression
error * √
1 + connectioncountpenalty * connectioncount
Sebuah jaringan dengan koneksi lebih akan memiliki kebugaran yang lebih negatif daripada jaringan dengan koneksi kurang. Saya menggunakan fungsi akar kuadrat karena saya merasa bahwa jaringan dengan 51 koneksi harus diperlakukan hampir sama dengan jaringan 50 koneksi, sementara jaringan dengan 5 koneksi harus diperlakukan sangat berbeda dari jaringan dengan 4 koneksi. fungsi utilitas cekung lain mungkin mencapai efek yang sama. Di satu sisi, seperti regularisasi L2 pada bobot, jenis hukuman adalah bentuk regularisasi pada struktur jaringan saraf itu sendiri.
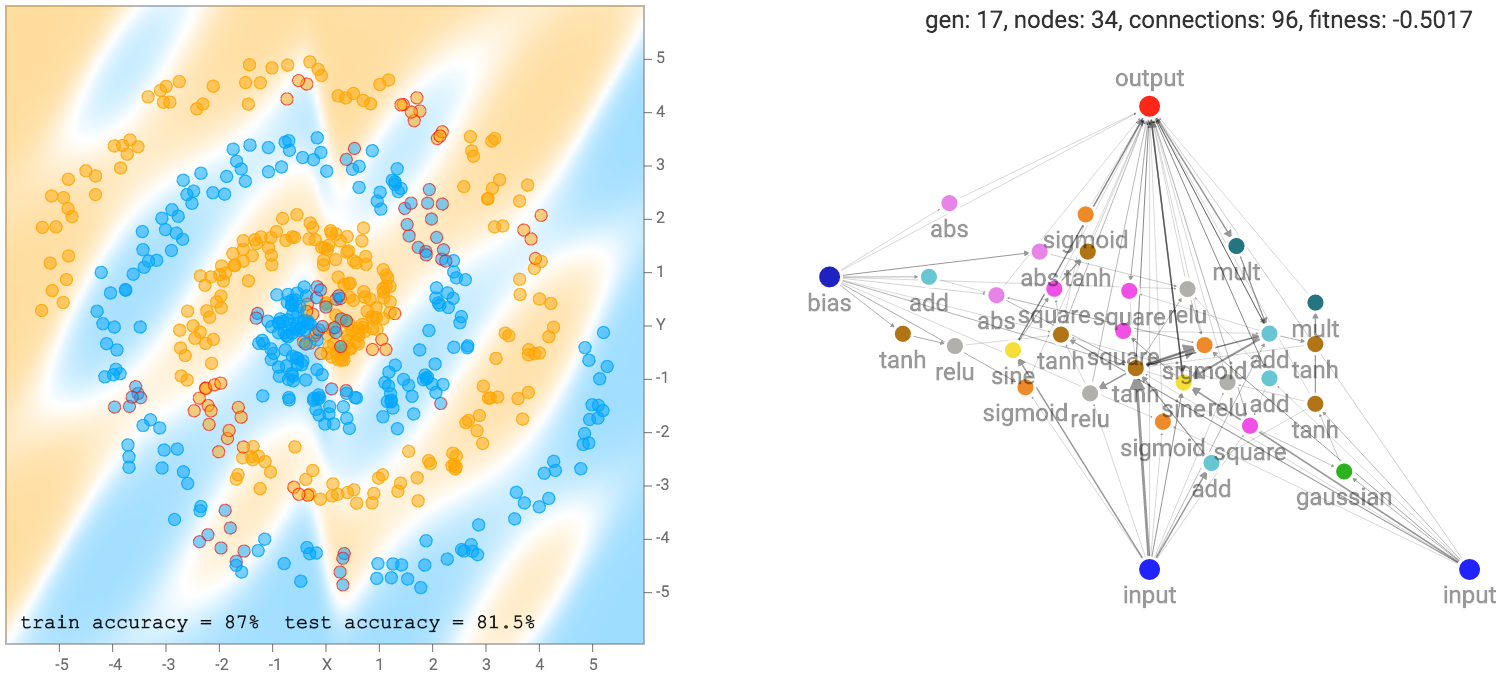
Setelah beberapa generasi langkah evolusi NEAT bersama dengan melakukan backprop pada setiap jaringan sebelum menghitung skor kebugaran, kita berakhir dengan beberapa jaringan yang mencoba mencocokkan data pelatihan:
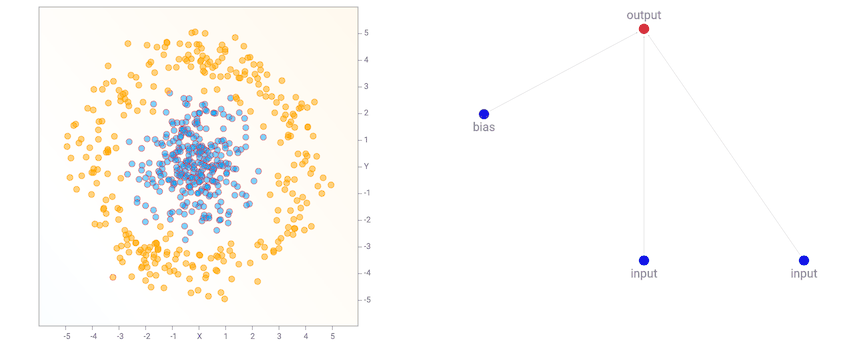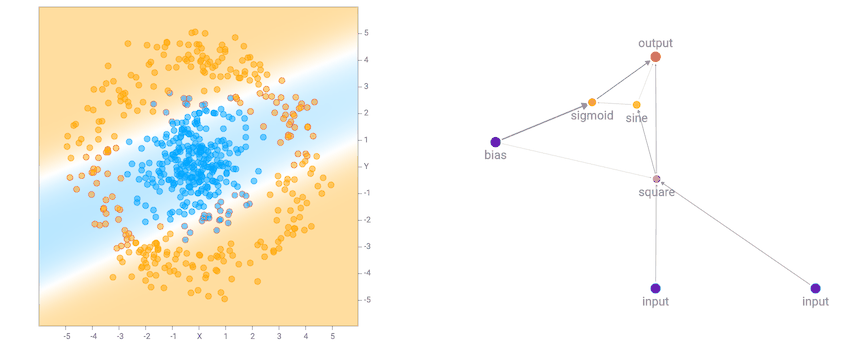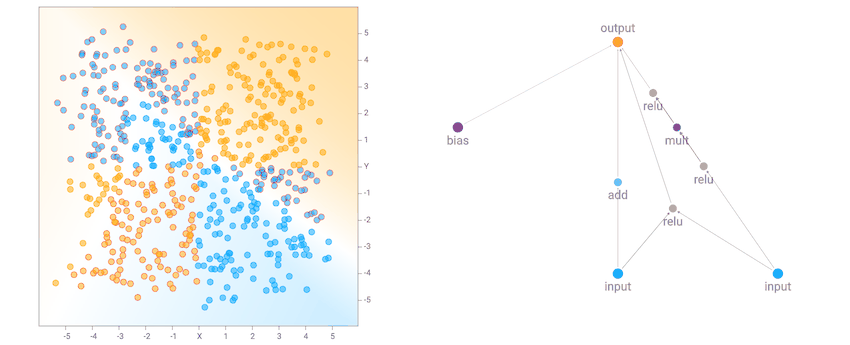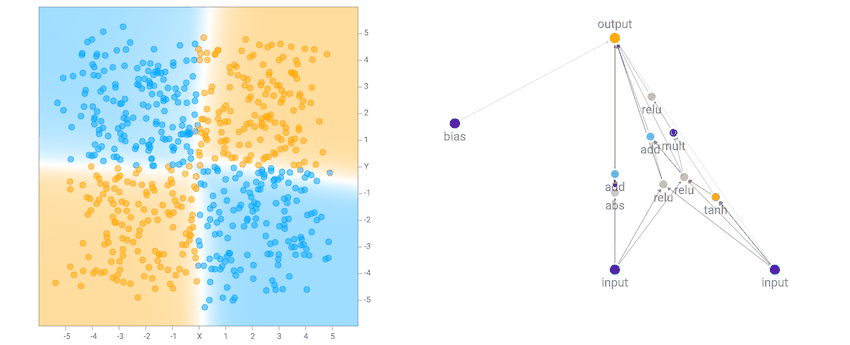
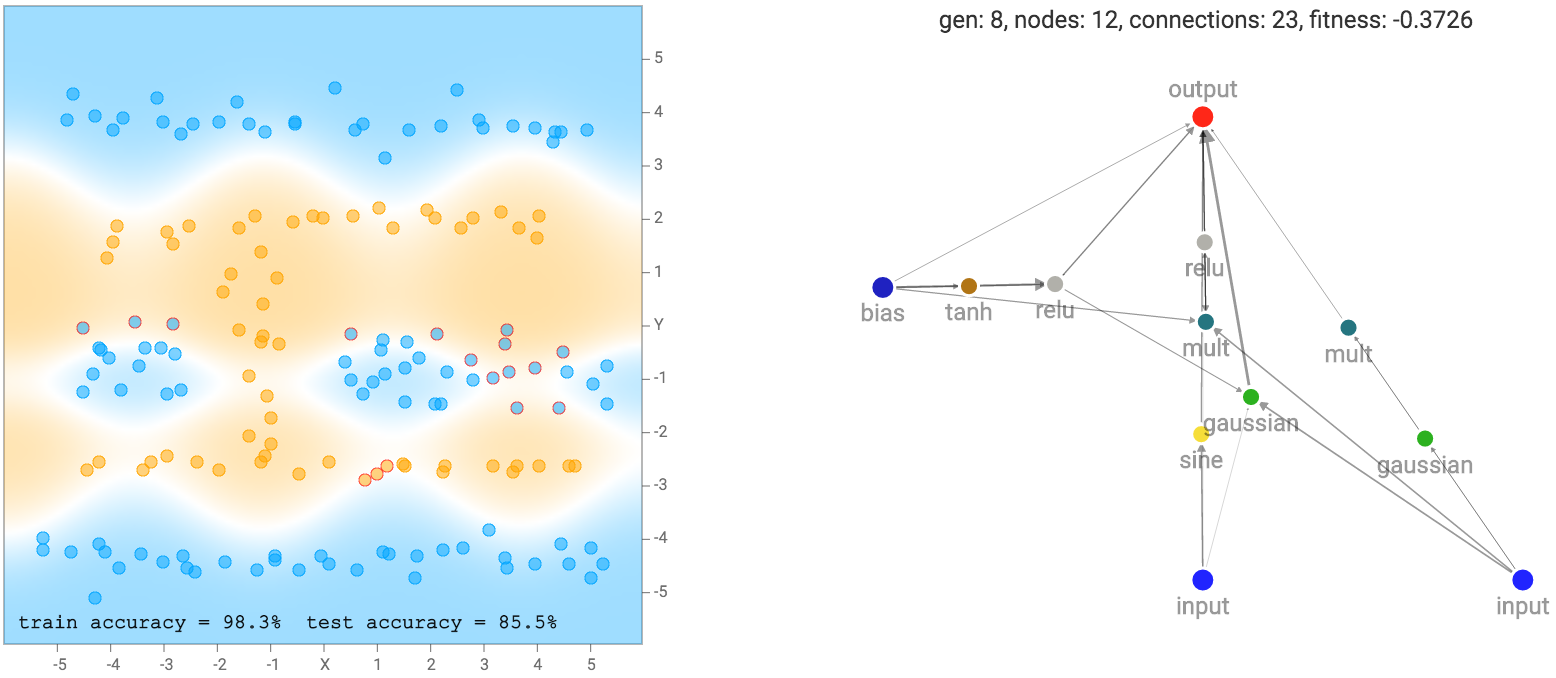
set data yang lebih rumit, seperti dataset spiral akan membutuhkan jaringan yang lebih rumit agar sesuai dengan data training.
Seperti disebutkan sebelumnya, jaringan kami tidak terbuat dari banyak lapisan terstruktur neuron, dan masing-masing neuron dapat terhubung ke neuron lain dalam jaringan. Oleh karena itu, kadang-kadang bahkan loop berulang dapat dibentuk, seperti ketika koneksi keluaran menghubungkan kembali ke neuron tersembunyi. Ini menyajikan masalah bagi kami ketika memutuskan bagaimana untuk melintasi jaringan saraf.
Untuk jaringan saraf konvensional umpan-maju di TensorFlow Playground, adalah mungkin untuk menuliskan dalam satu baris dari matematika yang menggambarkan output sebagai satu set bersarang fungsi dari input, seperti output = f_1 \ kiri (w_1 f_2 \ kiri (w_0x + b_0 \ right) + b_1 \ right) output = f 1 (w 1 f 2 (w 0 x + b 0) b 1) untuk + a 2 layer umpan maju net, atau bahkan output = f_1 \ kiri (w_1x + w_2 f_2 \ kiri (w_0x + b_0 \ right) + b_1 \ right) output = f 1 (w 1 x + w 2 f 2 (w 0 x + b 0) + b 1) untuk ResNet 2 layer. Jadi adalah mungkin untuk menentukan nilai output persis untuk setiap masukan untuk pakan arsitektur maju tersebut. Namun, untuk jaringan besar yang dihasilkan oleh NEAT, dengan banyak koneksi berulang gila, mungkin sangat sulit, atau bahkan tidak mungkin untuk mengungkapkan output sebagai fungsi dari input kita dapat menghitung dalam satu langkah.
Untuk menemukan output, kita hanya bisa menyebarkan setiap koneksi bersama-sama satu langkah pada satu waktu, jadi jika jarak terpendek antara input x dan output terdiri dari 3 koneksi, maka akan memakan waktu setidaknya 3 langkah untuk mendapatkan nilai output yang tergantung pada input, jika nilai output akan menjadi nol. Setelah mendapatkan output, kita dapat menggunakan backprop dengan cara seperti backpropagation melalui waktu ketika pelatihan jaringan berulang. Sinyal output juga akan menjadi fungsi dari waktu, atau lebih tepatnya fungsi dari seberapa banyak langkah kita menyebarkan jaringan dengan. Pertanyaannya adalah kapan kita berhenti menyebarkan sinyal ke depan untuk tujuan merekam nilai output untuk digunakan dalam klasifikasi? Saya telah melakukan beberapa pemikiran tentang topik ini dan menuliskan pikiran saya dalam sebuah posting blog sebelumnya. Pada akhirnya saya memilih untuk metode kedua untuk berhenti ketika setiap neuron telah menyentuh setidaknya sekali, dan saya pikir itu adalah keseimbangan yang baik antara pilihan yang saya miliki.
Proses evolusi
Dalam implementasi saya, saya menyimpan ukuran populasi tetap 100 jaringan. Seperti yang dibahas sebelumnya, saya menggunakan algoritma K-Medoids untuk memperbaiki jumlah sub populasi untuk 5, sehingga seluruh penduduk akan dikelompokkan ke dalam 5 set 20 jaringan yang mirip satu sama lain.
Pada langkah evolusi, generasi berikutnya dari masing-masing sub jaringan akan dibuat secara acak memilih dua jaringan dari generasi sebelumnya di sub jaringan yang sama (bisa jaringan yang sama yang dipilih dua kali), tertimbang oleh porportional probabilitas untuk skor kebugaran, sehingga jaringan scoring yang lebih baik akan memiliki kemungkinan lebih tinggi untuk mendapatkan dipilih untuk kawin dan menghasilkan keturunan untuk generasi berikutnya. Operator Crossover + mutasi genetik di NEAT akan diterapkan dalam langkah ini, sehingga keturunan pada generasi berikutnya akan memiliki rata-rata lebih neuron dan koneksi dibandingkan dengan generasi sebelumnya. Di sinilah jenis baru dari fungsi aktivasi dari jenis neuron yang berbeda akan eksperimen dipilih untuk generasi berikutnya untuk melihat apakah mereka akan meningkatkan jaringan.
Tapi kadang-kadang generasi berikutnya tidak benar-benar menawarkan perbaikan sama sekali dibandingkan dengan generasi sekarang, dan jika ada, semua neuron baru dan koneksi dapat berguna untuk tugas di tangan. Untuk mengatasi ini, saya juga tetap terbaik 10 jaringan dari generasi sebelumnya dan menyimpannya di aula khusus gen ketenaran untuk melestarikan untuk generasi berikutnya sehingga yang terbaik dari setiap generasi akan dikloning untuk masa depan, hanya dalam kasus mereka anak-anak semua berubah bodoh dari orang tua mereka. Hal ini tidak mungkin bahwa anak Michael Jordan akan lebih baik dari Michael Jordan di basket. Di dunia ini, Anda mungkin harus bersaing dengan orang tua Anda di utama mereka.
Sebelum menghitung skor kebugaran dari setiap jaringan, kembali propagasi akan dilakukan untuk setiap jaringan untuk mengoptimalkan bobot mereka. Secara default, setiap jaringan akan backpropped 600 kali. Setelah itu, kesalahan regresi logistik mereka akan dikombinasikan dengan faktor untuk menghukum untuk jumlah koneksi untuk menghitung skor kebugaran masing-masing jaringan. Skor kebugaran akan digunakan lagi dalam proses evolusi berikutnya.
Setelah setiap generasi evolusi, ada 50% kemungkinan bahwa kita akan memaksa spesies melakukan termiskin punah dan membunuh semua 20 anggotanya. Untuk mengisi kesenjangan dari 20 tempat baru yang tersedia, kita membiarkan kinerja terbaik spesies dari generasi sebelumnya untuk menghasilkan 20 keturunan tambahan. Jika penguin tidak belajar terbang dari waktu ke waktu, kita akan membiarkan serigala di. Hal ini akan menyebabkan spesies kinerja terbaik untuk bercabang menjadi dua sub spesies dan berkembang di arah berpotensi berbeda setelah itu.
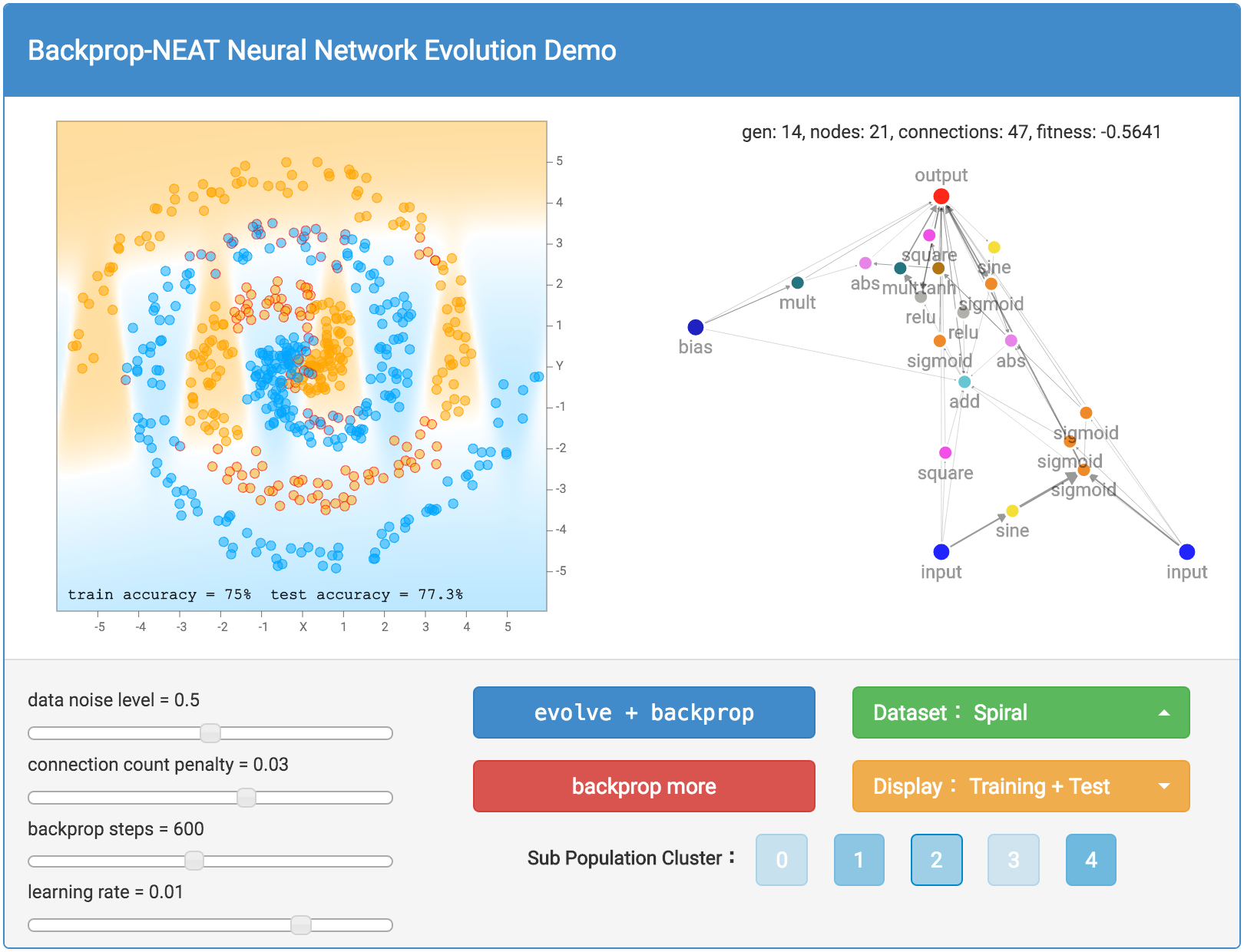
Menggunakan Demo
Oke, dengan rincian algoritma genetika, NEAT, dan backprop keluar dari jalan, kita dapat akhirnya mendiskusikan bagaimana untuk benar-benar menggunakan demo ini dan mengeksplorasi pilihan yang berbeda.
Pertama, kita bisa memilih dataset untuk bermain dengan dengan memilih satu melalui tombol hijau. Aku sudah mencerminkan dataset yang digunakan dalam demo TensorFlow Playground sehingga Anda dapat membandingkan hasil jika Anda ingin. Ada lingkaran kecil di dalam sebuah dataset besar lingkaran, dataset XOR, dataset yang terdiri dari 2 cluster gaussian, dan dataset spiral yang paling menantang. Jumlah keacakan setiap dataset dapat dikontrol dengan menggunakan data tingkat kebisingan bar geser di sebelah kiri. Anda juga dapat memilih untuk mengatur ulang dan regenerasi dataset Anda kapan saja. Saya juga sudah dimasukkan ke dalam mode dataset kustom sehingga Anda dapat menekan dalam dataset Anda sendiri dengan mouse atau trackpad.
Setengah dari data yang dihasilkan akan menjadi milik training set dan setengah dalam tes set. Anda dapat menggunakan tombol oranye untuk memilih yang menetapkan yang ingin ditampilkan.
 |
| entri kustom dataset. Data poin lebih banyak lebih baik. |
keajaiban terjadi dengan biru berevolusi + backprop tombol. tombol ini akan berkembang seluruh generasi 100 jaringan oleh satu generasi, dijelaskan pada bagian sebelumnya, dan kemudian melakukan backprop pada setiap jaringan dalam generasi baru yang tepat setelah itu. Kadang-kadang Anda mungkin ingin bereksperimen dengan backpropping jaringan lebih lanjut, jika Anda berpikir mereka belum mencapai optimums lokal mereka belum, karena hal ini dapat menjadi kasus untuk jaringan yang telah tumbuh sangat besar. Jadi saya termasuk backprop tombol lebih merah untuk memungkinkan propagasi kembali murni, dan tidak ada evolusi terjadi. Selain itu, kita dapat mengontrol berapa banyak langkah kita backprop oleh setiap waktu, dan juga tingkat belajar dengan menyesuaikan slider bar yang sesuai.
Setelah anda menekan baik berevolusi + backprop atau backprop hanya tombol, jaringan dengan skor kebugaran terbaik akan digambarkan dengan semua neuron dan koneksi ke sisi kanan layar. Sebuah jalur koneksi tebal berarti nilai absolut dari berat badan lebih besar. Daerah klasifikasi, dan akurasi klasifikasi juga akan dihitung dan ditampilkan di sisi kiri layar. Selain menggambar daerah klasifikasi, mispredicted sampel akan memiliki lingkaran merah kecil yang mengelilingi datapoint untuk menunjukkan kesalahan prediksi. Jumlah generasi, jumlah neuron dan jumlah koneksi, dan skor kebugaran jaringan terbaik akan dicetak di atas jaringan. Seperti dijelaskan sebelumnya, skor kebugaran juga tergantung pada faktor penalti menghitung koneksi, dan ukuran faktor ini dapat dikontrol oleh slider bar di bagian kiri bawah.
Jika Anda ingin melihat bukan hanya jaringan yang terbaik dalam populasi, ada juga pilihan untuk melihat jaringan terbaik di setiap dari 5 sub populasi. Ada tombol untuk setiap sub populasi cluster, dan jika Anda klik pada salah satu dari mereka, Anda akan mampu membawa dan menampilkan jaringan terbaik yang sub populasi dan semua informasi yang terkait akan didasarkan dari jaringan itu. Ini akan memungkinkan Anda untuk melihat struktur yang berbeda dari spesies yang berbeda dan menghargai (paksa) keragaman dalam populasi. Secara default, yang terbaik sub populasi, oleh karena itu jaringan terbaik akan dipilih untuk ditampilkan. Shading relatif dari warna untuk tombol penduduk sub didasarkan pada nilai fitness relatif bagi anggota terbaik dari masing-masing sub populasi. Semakin padat warna, yang kuat bahwa sub populasi akan relatif terhadap sub populasi lainnya.
hasil
Di asli TensorFlow Playground demo, pengguna bisa menipu dan menggunakan fitur standar, seperti mengkuadratkan input, mengalikan mereka, atau menempatkan mereka melalui sinusoid, dan kemudian makan di input dan semua fitur pra-diproses tangan direkayasa ini menjadi multi-layer jaringan saraf. Ini memiliki keuntungan bagi manusia untuk secara visual mengidentifikasi fitur dalam dataset, dan memilih fitur yang baik untuk menghitung untuk menyederhanakan tugas dari jaringan saraf. Sebagai contoh, jika dataset adalah lingkaran kecil di dalam lingkaran besar, kita tahu bahwa batas keputusan hanya jari-jari, atau bahkan kuadrat jari-jari, dari asal, sehingga dengan mengkuadratkan kedua input pertama, sebagian besar pekerjaan memiliki telah dilakukan untuk jaringan.
Apa yang saya tertarik untuk melihat adalah untuk algoritma genetika untuk menemukan fitur ini dengan sendirinya melalui proses evolusi, menggabungkan perhitungan fitur ini ke dalam jaringan saraf yang sebenarnya melalui set ekstra fungsi aktivasi yang tersedia, dan tidak bergantung pada rekayasa manusia. Jadi masukan baku untuk setiap jaringan NEAT hanya akan menjadi x dan y koordinat, dan nilai bias 1. Setiap fitur, seperti mengkuadratkan data, atau mengalikan mereka, atau menempatkan mereka melalui gerbang sinusoidal, harus ditemukan oleh algoritma.
Saya melihat bahwa untuk set kedua data lingkaran, itu lebih mungkin bahwa jaringan akhir terdiri dari banyak gerbang sinusoidal, persegi atau abs aktivasi, yang masuk akal mengingat simetri dataset. Untuk dataset XOR, ada cenderung lebih relu aktivasi, yang diperlukan untuk menghasilkan batas keputusan yang garis lebih atau kurang lurus dengan sudut tajam.
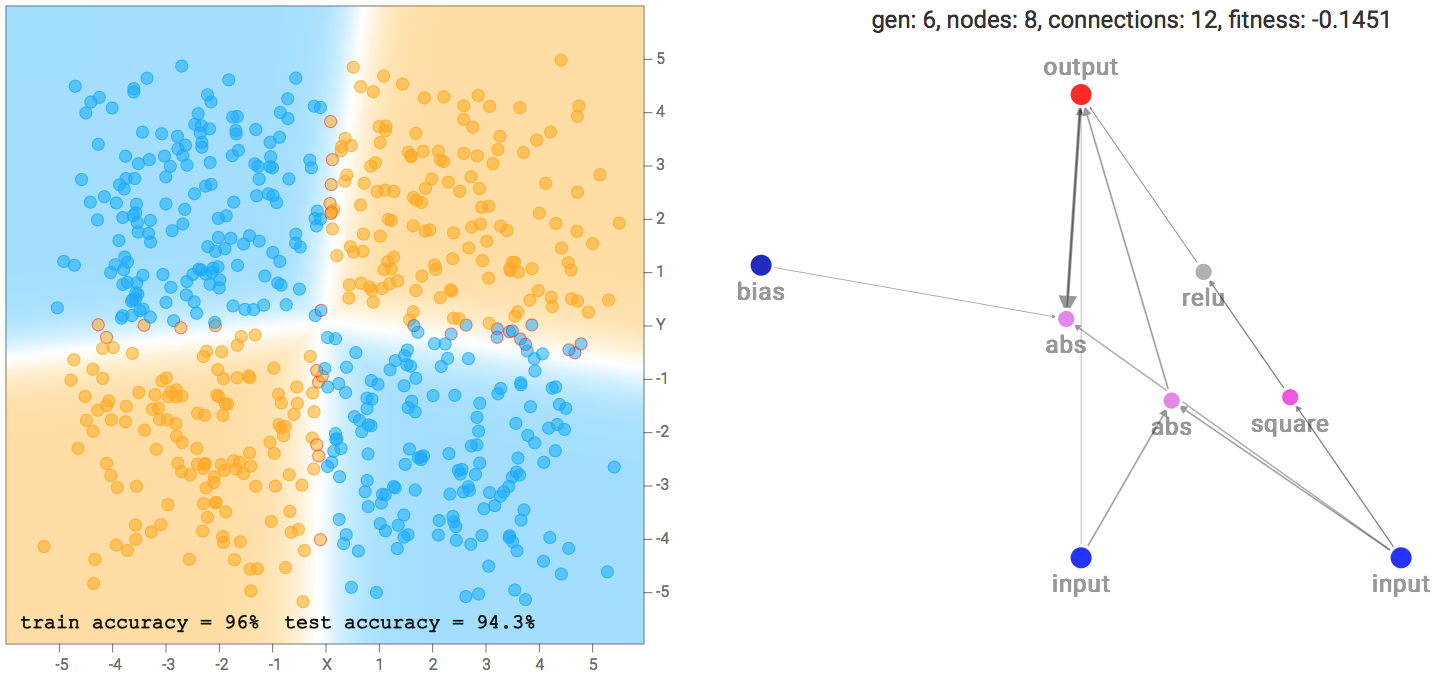 |
| XOR Dataset Solusi Contoh |
Salah satu hal yang lebih menarik yang saya perhatikan adalah bahwa jaringan yang backprop juga akan cenderung disukai dalam proses evolusi, dibandingkan dengan jaringan jahat dengan gradien yang meledakkan, karena jaringan dengan diledakkan nilai berat badan kemungkinan akan memberikan hasil klasifikasi sampah yang akan menghasilkan skor kebugaran miskin. Menetapkan rendahnya jumlah langkah backprop, atau tingkat belajar yang besar, dapat menyebabkan algoritma genetika untuk menghasilkan berbagai jenis jaringan yang akan tampil lebih baik di lingkungan mereka.
Jadi, bahkan jika ada satu set bobot untuk jaringan tertentu yang dapat cocok dengan data pelatihan persis, jika kondisi backprop tidak memungkinkan jaringan yang mengetahui bahwa set beban, mungkin berakhir menjadi dibuang oleh evolusi. Mungkin analogi dalam kehidupan akan bahwa orang-orang dengan extrodinarily tinggi IQ mungkin tidak pernah mencapai potensi penuh mereka jika mereka tinggal di lingkungan yang sangat keras selama era barbar yang mendukung kekuatan fisik baku dan keinginan untuk memangsa yang lemah. Atau di zaman modern, orang dengan kecerdasan baku yang tinggi juga mungkin gagal untuk maju jika mereka tidak memiliki keterampilan orang untuk mempengaruhi rekan-rekan mereka di masyarakat untuk menerima ide-ide mereka.
Pekerjaan masa depan
Selain masalah klasifikasi, saya telah membuat sebuah demo serupa sebelumnya untuk mendapatkan Backprop NEAT untuk bekerja pada masalah regresi. Di bawah ini adalah demo sederhana untuk regresi jika Anda tertarik. Dalam demo ini, semua lima hasil populasi sub diplot di kanvas untuk perbandingan yang lebih baik.
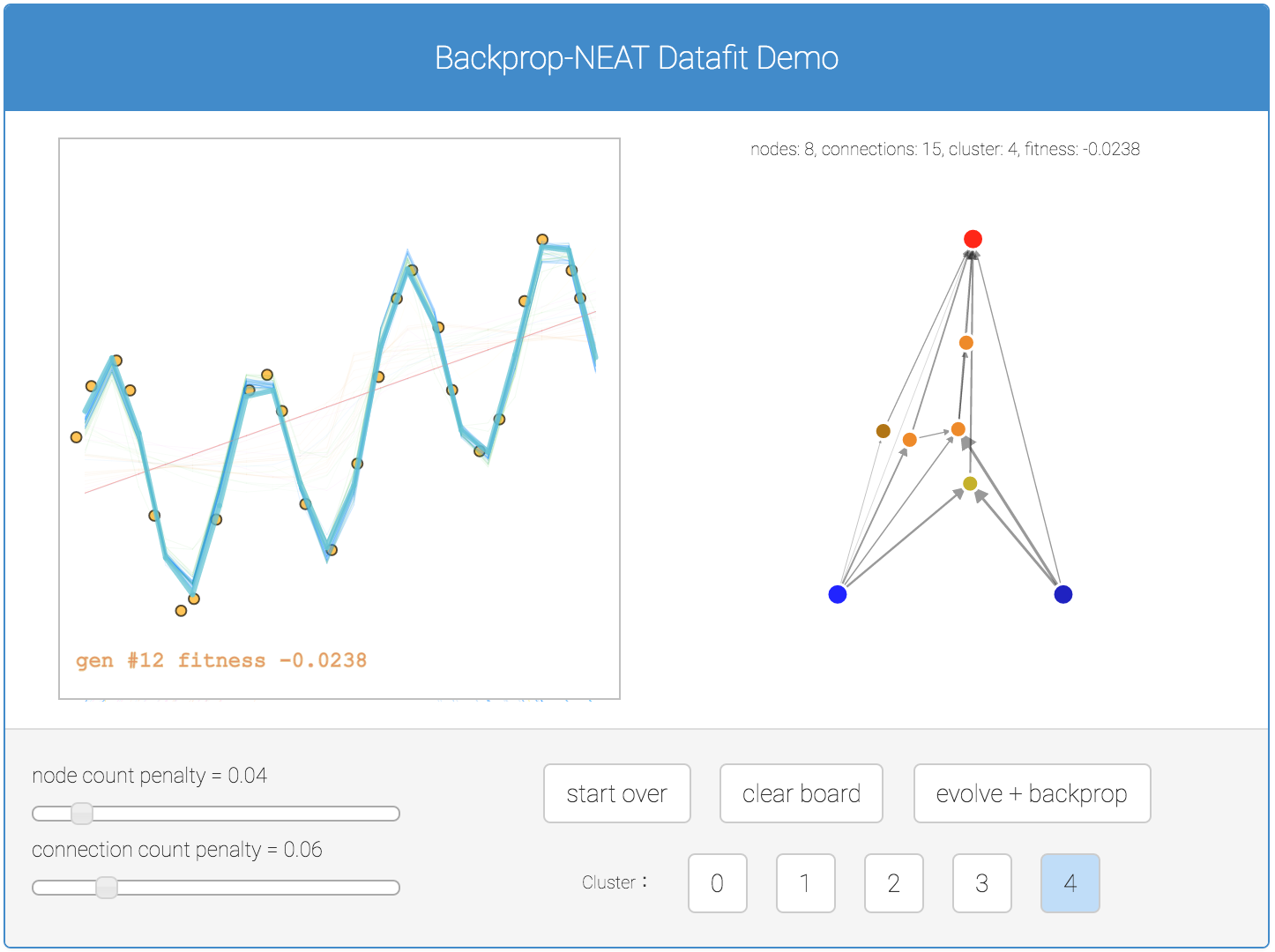
Salah satu tugas saya tertarik untuk melihat karya neuroevolution pada adalah dengan menggunakan evolusi untuk menemukan jenis baru dari blok bangunan jaringan saraf kecil, seperti LSTM blok, yang sering diulang dalam jaringan saraf dalam jauh lebih besar, atau jaringan saraf berulang. Diberi tugas belajar yang mendalam tertentu, dan sejumlah besar GPU (yang menjadi lebih terjangkau setiap beberapa bulan), mungkin di masa depan dapat layak untuk melatih 100 jaringan yang mendalam secara paralel, beberapa lusin kali, didasarkan pada berkembang kecil blok bangunan saraf komponen jaringan, dan melihat apakah Novel blok jaringan baru kecil dapat ditemukan yang sangat baik untuk memecahkan masalah-masalah tertentu.
 |
| Mungkin "A" bisa berkembang? (Sumber: Colahs posting blog pada LSTMs) |
Berkat banyak teman yang membantu saya test drive saraf evolusi jaringan bermain demo sebelumnya, dan untuk umpan balik yang berharga digunakan untuk finetune dan memperbaikinya.